11.2 DB 핵심 이론
이번 강좌에서는 관계형 데이터베이스의 기본적인 개념과 주요 구성요소 및 용어들을 배운다. 테이블에서 부터 키와 제약조건, 인덱스, 시퀀스 등을 이해하고 SQL을 배우기 전에 꼭 필요한 필수적인 개념과 용어들을 살펴봅니다.
이 강의를 통해 관계형 데이터베이스의 구조와 데이터베이스 관리를 위한 구성요소들에 대해 이해할 수 있게 됩니다.
테이블(Table)
테이블은 관계형 데이터베이스에서 데이터 관리의 기본이 되는 구조 이다. 데이터들이 가지는 공통적인 속성들을 모아 정의한 컬럼(필드)들로 구성되며 컬럼에 저장되는 데이터는 숫자형, 문자형, 날짜형, boolean 등으로 구분되며 파일과 같은 바이너리 데이터를 저장하거나 매우 긴 텍스트를 저장하기 위한 자료형을 가진다.
예를 들어 다음과 같은 데이터가 있다고 가정하자.
김길동, AA대학교, 1999-10-21, kim@aa.com
park@bb.com, 박사랑, BB대학교, 2000-01-21
나최고, 1998-07-11, na@cc.com, CC대학교
김길동, BB대학교, 1999-03-10, kim@bb.com
정리가 되어 있지는 않지만 데이터의 내용을 보면 이름, 대학, 생년월일, 이메일로 공통된 정보를 가지고 있다고 볼 수 있다. 이를 테이블로 표현하면 다음과 같다.
| 이름 | 대학 | 생년월일 | 이메일 |
|---|---|---|---|
| 김길동 | AA대학교 | 1999-10-21 | kim@aa.com |
| 박사랑 | BB대학교 | 2000-01-21 | park@bb.com |
| 나최고 | CC대학교 | 1998-07-11 | na@cc.com |
| 김길동 | BB대학교 | 1999-03-10 | kim@bb.com |
컬럼(Column)
테이블을 구성하는 기본 속성으로 필드, 애트리뷰트 라고도 한다.
앞의 예시에서 이름, 생년월일, 대학, 이메일이 컬럼이 된다. 각각의 컬럼에 저장되는 데이터는 동일한 타입이어야 하며 구체적인 자료형은 데이터베이스 마다 차이가 있다.
로우(row)
컬럼에 해당하는 데이터들을 가지고 있는 하나의 데이터셋을 말하며 레코드 혹은 튜플 이라고도 한다.
앞의 예시에서 한 사람의 데이터 즉 김길동, AA대학교 , 1999-10-21 , kim@aa.com 이 로우가 된다. 예시에서는 총 4개의 로우가 있다고 이야기할 수 있다.
자료형
컬럼에 들어갈 수 있는 데이터의 유형으로 일반적으로 숫자형, 문자형, 날짜형, boolean 등으로 구분
데이터베이스 마다 사용하는 자료형의 이름에 차이가 있다. 예를 들어 숫자의 경우 오라클은 number, MySQL은 int, double 등을 사용한다. 일반적인 자료형 이외에 파일과 같은 바이너리 데이터를 저장하거나 매우 긴 텍스트를 저장하기 위한 자료형등이 별도로 존재하며 이러한 특수 타입들은 데이터베이스 마다 지원하는 범위가 다르다. 또한 최근에는 JSON 데이터의 활용이 늘어남에 따라 JSON 데이터를 저장하기 위한 컬럼 구조 혹은 변환 함수등을 제공하기도 한다.
스키마와 ERD
데이터베이스 스키마는 데이터베이스에서 자료의 구조, 자료의 표현 방법, 자료 간의 관계를 형식 언어로 정의한 구조를 말하며 ERD는 Entity Relationship Diagram 의 약어로 시각적으로 스키마를 설계할때 사용하는 방법중 하나이다.
제대로 스키마를 설계하는것은 전문적인 영역으로 많은 경험과 노하우가 필요한 작업으로 여기서는 데이터베이스를 배우기 위해 꼭 알아야 하는 내용들만 간략히 살펴본다.
스키마(Schema)
스키마는 일반적으로 데이터베이스 구조를 객체, 속성, 관계, 제약조건등을 포함해 설명한 설계도이며 보통 3계층 구조로 표현 한다.
- 외부 스키마(External Schema) : 프로그래머나 사용자의 입장에서 데이터베이스의 모습으로 조직의 일부분을 정의한 것. 즉, 외부에 노출되는 구조로 하나의 데이터베이스에 여러 외부 스키마가 존재할 수 있음.
- 개념 스키마(Conceptual Schema) : 모든 응용 시스템과 사용자들이 필요로하는 데이터를 통합한 조직 전체의 데이터베이스 구조를 논리적으로 정의한 것. 일반적으로 스키마라고 하면 개념 스키마를 말함.
- 내부 스키마(Internal Schema) : 전체 데이터베이스의 물리적 저장 형태를 기술하는 것. DBA(DataBase Administrator)에 의해 생성되고 관리되는 영역.
데이터베이스(DBMS) 종류에 따라 물리적으로 데이터 저장을 위한 테이블을 생성하기 위해서는 먼저 해당 데이터가 관리될 스키마 혹은 데이터베이스를 생성 하거나 지정해야 한다. 데이터베이스에 따라 스키마 혹은 데이터베이스라는 용어가 혼재되어 사용된다.(오라클은 스키마, MySQL, H2 는 데이터베이스)
ERD(Entity Relationship Diagram)
보통 관계형 데이터베이스를 설계할때 많이 사용하는 다이어그램 이다. 시각적인 도형과 선등을 이용해 데이터의 관계를 정의하는 방식으로 전문적인 도구를 사용하거나 단순히 ppt, visio 등의 프로그램을 이용하기도 한다.
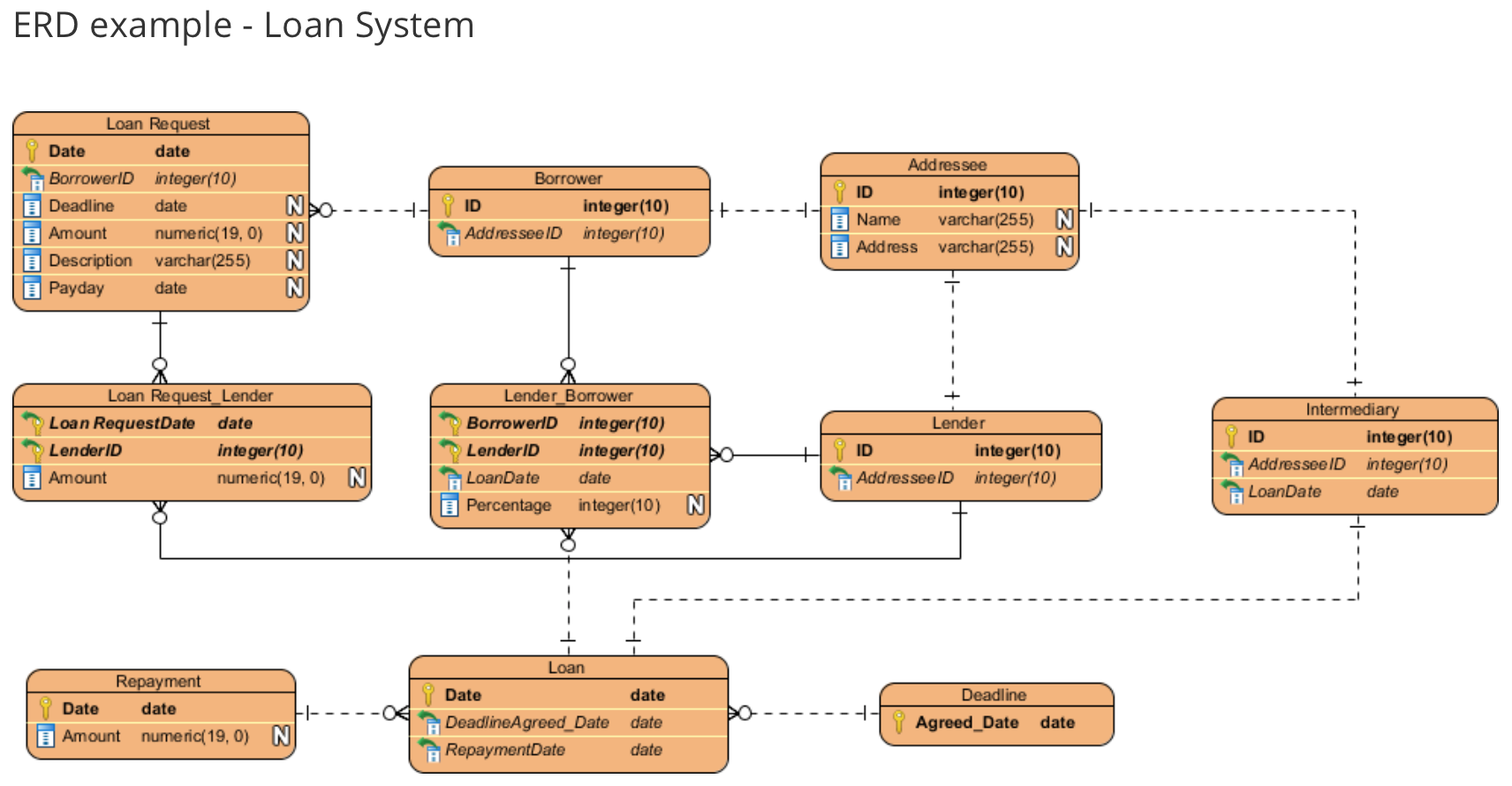
ERD는 엔티티, 속성, 관계로 구성된다.
엔티티(Entity)
- 둥근 사각형으로 표현
- 엔티티 이름은 단수형이고 유일
- 시스템화 하고자 하는 사물이나 사건 혹은 현실 세계의 객체
- 모든 Entity는 하나 이상의 식별자 (UID : Unique Identifier)을 가져야한다.
- UID가 없다면 Entity가 아님
- 예) 회원, 학생, 주문, 상품 등
속성(Attribute)
- 속성 이름은 소문자로 작게 표기.
- 엔티티 이름과 속성 이름이 같으면 안됨.
- ”#” 은 UID. “*“는 필수(Mandatory). “o”는 선택(Optional)을 의미
- 자신의 속성이 아닌데 관계를 위해 자신의 속성으로 표시해서는 안된다.
- 예) 이름, 전화번호, 상품번호, 상품명 등
관계(Relationship)
- 두 엔티티 사이에 선을 긋고 관계 명칭을 기록.
- 점선은 선택 (may be)을 의미(회원과 주문의 관계, 주문이 있을수도 있고 없을수도 있음)
- 실선은 필수 (must be) 를 의미 (주문의 경우 회원, 상품 정보가 반드시 필요)
- 관계 형태(Cardinality)를 표시한다.
- 1:1, 1:다, 다:다 등의 관계로 정의.
제약 조건과 키
제약 조건(Constraint)
데이터베이스에서 제약조건이란 컬럼에 부여하는 일종의 속성으로 저장될 데이터에 대한 요구사항이라고 볼 수 있다. 데이터를 저장하는 프로그램측에서 특정 조건을 만족하는 경우에만 저장하도록 로직을 설계할 수는 있지만 로직에 의한 오류도 있을수 있으며 프로그램을 통하지 않고 들어오는 데이터의 경우에는 잘못된 데이터가 저장되는 것을 원천적으로 차단할수는 없다.
제약 조건은 데이터베이스 자체적으로 저장될 데이터에 대한 요구 조건을 설정하는 것으로 제약 조건을 벗어나는 데이터는 원천적으로 저장이 차단된다. 이는 데이터베이스의 무결성(Integrity)을 지키기 위한 방법이 된다.
대표적인 제약 조건은 다음과 같다.
| 종류 | 설명 | 비고 |
|---|---|---|
| NOT NULL | 컬럼에 데이터를 비워둘 수 없음 | 기본은 NULL 가능 |
| UNIQUE | 주키는 아니지만 중복값 허용 안함 | 기본은 중복 가능 |
| Primary Key | 데이터의 유일성을 보장하는 컬럼 | NOT NULL + UNIQUE, 테이블에 하나만 설정가능 |
| Foregin Key | 두 테이블간의 참조 무결성을 보장 | 외래키로 지정된 컬럼값은 참조 테이블에 존재하는 값만 사용 가능 |
| CHECK | 저장할 값의 범위 등을 지정 | 숫자범위, 다른 컬럼 값 비교 결과, 특정 문자중 하나 등 |
| IDENTITY | 유일한 값을 가지는 id컬럼 | PK, Not Null, auto_increment 자동 적용됨 |
MySQL의 경우 CHECK 제약조건은 8.0.16 이후 버전에서만 지원되니 참고바란다.
키(Key)
관계형 데이터베이스에서 제약 조건중 하나인 키는 데이터의 유일성 및 관계 설정의 목적에 사용된다. 적절한 키의 사용은 데이터베이스 설계에 있어 매우 중요한 요소 이다.
PK(Primary Key)
주 키, 기본 키, 프라이머리 키 라고도 한다. 테이블에 저장된 레코드(로우)를 서로 구분할 수 있도록 특정 컬럼에 설정하는 제약 조건이다. PK가 존재하지 않으면 데이터가 중복되고 특정 데이터를 검색하기 어려워 진다.
예를 들어 앞의 학생정보 테이블 예에서 김길동 학생이 두명이 있기 때문에 이름으로 검색할 경우 두명의 학생이 검색된다. 따라서 이러한 경우 이름만으로는 유일성 확보가 안되기 때문에 생년월일, 학교등 부가적인 컬럼의 정보를 조합해야 하는 어려움이 발생한다.
그러면 이름을 PK로 지정하는 것을 생각해 볼 수 있는데 이름의 경우중복이 가능하기 때문에 별도의 중복되지 않는 값이 필요하다. 쉽게 생각할 수 있는 것은 학번, 주민등록번호등의 고유번호 이다. 그러나 이들 번호는 개인정보에 해당하므로 외부에 노출되지 않는 것이 좋기 때문에 PK로는 부적합 하다.
보통 PK는 시퀀스(Sequence)라고 불리우는 단순 증가 값을 사용한다. 그냥 0부터 시작해서 1씩 증가하는 숫자로 이 숫자의 의미는 단순히 데이터들을 서로 구분하는 용도로만 사용한다고 이해하면 된다.
FK(Foreign Key)
외래 키는 테이블간의 관계를 설정하기 위해 사용하며 참조 무결성을 제공하기 위한 용도로 사용된다.
앞의 학생정보 테이블에서 학교 컬럼의 자료형은 문자열로 다음의 데이터는 모두 동일 학교를 의미한다.
AA대학교, AA 대학교, 에이에이 대학교, A A 대학교, AA대학 ...
이경우 데이터의 의미는 동일하지만 검색에서 문제가 발생한다. AA대학교 학생들만 검색 한다면 다른 이름들은 같의 의미지만 검색이 안되며 AA대학교 or AA 대학교 or 에이에이 대학교 ... 와 같이 조건 검색을 해야 한다.
이러한 문제를 원천적으로 차단하기 위해서는 등록 가능한 학교테이블을 별도로 두고 이를 참조할 수 있도록 외래키를 등록해 사용해야 한다.
대학정보 테이블은 다음과 같이 만들수 있으며 이때 대학코드를 PK로 설정 한다.
| 대학코드(PK) | 대학명 | 위치 |
|---|---|---|
| 10011 | AA대학교 | 서울 |
| 10012 | BB대학교 | 인천 |
| 10013 | CC대학교 | 대전 |
학생정보 테이블은 다음과 같이 수정되며 대학 컬럼은 FK로 설정 하고 학교이름 대신 대학코드를 등록 한다.
| 이름 | 대학(FK) | 생년월일 | 이메일 |
|---|---|---|---|
| 김길동 | 10011 | 1999-10-21 | kim@aa.com |
| 박사랑 | 10012 | 2000-01-21 | park@bb.com |
| 나최고 | 10013 | 1998-07-11 | na@cc.com |
| 김길동 | 10012 | 1999-03-10 | kim@bb.com |
이때 학생정보 테이블의 대학 컬럼에 대학정보 테이블에 없는 값을 등록하는 경우 에러가 발생하고 데이터가 등록되지 않는다. 또한 대학코드 테이블에서 특정 대학을 삭제하는 경우에도 해당 데이터를 학생정보 테이블에서 참조하고 있기 때문에 단순한 삭제 쿼리로는 데이터가 바로 삭제 되지 않는다.
인덱스와 시퀀스
인덱스(Index)
인덱스는 데이터베이스에서 데이터 검색의 속도 향상을 위해 사용하는데 예를 들어 앞의 학생정보 테이블에 10만건의 학생정보가 들어있고 이중에서 홍길동이라는 이름을 가진 학생들만 찾아야 한다고 가정해 보자. 학생정보는 등록순으로 저장되고 데이터베이스에서 데이터를 저장하는 위치는 순차적이지 않기 때문에 별도의 장치가 되어 있지 않다면 전체 데이터를 하나씩 읽어가면서 이름이 일치하는 로우만 추출해야 한다.
만일 데이터가 이름순으로 정렬되어 있다면 홍으로 시작되는 위치에서 시작해 데이터를 차례로 찾으면 되기 때문에 10만건 모두를 검색할 필요가 없게된다.
이와같이 인덱스는 하나 혹은 여러 컬럼을 이용해 데이터 검색을 위한 별도 자료구조를 생성하는 것으로 PK로 지정된 컬럼은 자동으로 인덱스가 생성 된다. PK 이외의 컬럼을 이용한 검색이 필요한 경우 해당 컬럼을 이용해 별도의 인덱스 설정이 필요하다.
다음은 인덱스를 생성하는 예 이다.
// 테이블 생성시 추가하는 경우
CREATE TABLE test (
keyword varchar(20),
INDEX(keyword(20))
)
// 테이블 생성 이후 추가하는 경우
ALTER TABLE test ADD INDEX(keyword(20));
시퀀스(Sequence)
시퀀스는 PK컬럼을 관리하기 위해 사용하는 데이터베이스 객체로 보통 데이터 추가시 순차적으로 증가하는 값을 자동으로 생성한다.
최근의 데이터베이스들은 auto increment, auto_increment 와 같은 속성을 컬럼에 추가하는 것으로 자동증가 값을 사용할 수 있지만 대표적인 RDBMS인 오라클의 경우 별도의 시퀀스 객체를 사용한다.
H2 의 경우 IDENTITY라고 하는 자료형이 제공되어 auto_increment 를 대체해 사용하는것도 가능하다.
별도의 시퀀스 객체를 사용하는 방식은 다소 불편하고 데이터베이스간 호환성에도 문제를 발생 시킨다. 예를 들어 MySQL 이나 H2 의 경우 PK 에 auto increment 를 지정한 경우 데이터 등록시 PK컬럼을 빼고 나머지 데이터만 등록하면 자동으로 입력되는 방식이라 편리하지만 오라클의 경우 시퀀스 객체를 사용하는 쿼리를 작성해야 하므로 쿼리에 호환이 안되는 문제가 있다.
PK 시퀀스 등록 쿼리 예
// MySQL, H2, 트리거 사용시 Oracle 도 동일 쿼리 사용가능
insert into student(name, school, email) values('홍길동','AA대학교','test@test.com');
// Oracle
insert into student(id, name, school, email) values(id_seq.nexval, '홍길동','AA대학교','test@test.com');
이러한 문제 해결을 위해서는 오라클에서 시퀀스이외에 트리거라는 것을 만들어 데이터 추가시 자동으로 시퀀스 객체를 참조해 값을 추가하도록 하는 방법이 있다. 이 경우 별도로 트리거를 생성 하는 번거로움은 있지만 다른 데이터베이스와 동일한 쿼리를 사용할 수 있다는 장점이 있다.
오라클에서 트리거를 이용한 auto increment 구현
REATE OR REPLACE TRIGGER s_id
BEFORE INSERT ON student
FOR EACH ROW
BEGIN
SELECT id_seq.NEXTVAL
INTO :new.id
FROM dual;
END;
트리거는 특정 이벤트 발생시 자동으로 처리하는 간단한 자동처리 작업으로 다음에서 자세히 알아 본다.
트리거, 함수, 트랜잭션
트리거(Trigger)
트리거는 방아쇠라는 뜻이고 총의 방아쇠를 당기면 내부에서 일련의 작업이 이루어지고 총알이 발사되는 원리에 착안해 붙여진 이름이다. 데이터베이스에서는 특정 테이블에 데이터 조작(inser, update, delete 와 같은 DML 문의 실행)시 데이터베이스에서 자동으로 동작하도록 작성된 일종의 프로그램으로 볼 수 있다.
오라클에서 시퀀스를 이용해 자동으로 컬럼값을 증가시키는 트리거 예제와 같이 트리거는 특정 이벤트가 발생했을때 관련된 처리를 진행하는 코드가 추가되는 구조이다.
SQL3 표준에 포함되어 대부분의 상용 DBMS에서 제공되고 있다. 다만 기본 구문은 동일 하지만 처리를 구현하는 코드 영역은 데이터베이스마다 다소 차이가 있으므로 구체적인 사항은 해당 데이터베이스의 매뉴얼을 참고하도록 한다.
함수(Function)
함수는 프로그램안에서 특정 기능을 수행하는 독립 코드를 의미한다. 보통 파라미터(인자)와 리턴값을 통해 다양한 조건에서 동작하도록 설계되어 재사용이 가능한 구조이다.
데이터베이스도 함수를 가지고 있으며 SQL을 통해 데이터를 좀 더 쉽게 다룰 수 있도록 하기 위해 만들어졌다. 이러한 함수는 SQL에 포함된 표준함수도 있지만 데이터베이스마다 지원되는 고유의 함수도 있다.
경우에 따라서는 데이터베이스 함수 사용은 프로그램의 코드를 줄여주기 때문에 당장은 편할수 있으나 이 경우 프로그램이 특정 데이터베이스에 종속되는 결과를 낳을수 있기 때문에 전용 함수 사용에는 신중을 기해야 한다.
대표적인 표준 함수들에 대해서는 뒤에서 배우게될 SQL 에서 살펴보도록 한다.
트랜잭션(Transaction)
프로그램에서 어떤 이벤트가 발생했을때 경우에 따라서는 하나의 테이블에만 데이터를 변경할 수 있지만 많은 경우 여러 테이블의 데이터를 차례로 변경해야 하는 경우가 발생 한다.
예를 들어 은행에서 계좌이체를 한다고 가정해 보자. 동일 은행의 A -> B 계좌로 이체한다고 했을때 계좌는 테이블로 볼 수 있다. 이때 A계좌에서 100만원을 차감한후 B계좌에 100만원을 추가하면 계좌이체가 완료되는 것이다. 이때 A 계좌에서 차감후 B 계좌에 추가하는 과정에서 에러가 발생하면 A 계좌에서 차감했던 금액은 다시 원래대로 되돌려야 한다.
이처럼 트랜잭션은 하나의 논리적 기능을 수행하기 위해 여러 작업을 묶어서 처리하는 것을 의미한다. 이러한 트랜잭션은 프로그램에서 단위 작업마다 성공 여부를 체크해서 진행할 수도 있으나 이 경우 개발자가 로직을 잘못 설계할 가능성도 있기 때문에 데이터베이스 혹은 미들웨어 레벨에서 처리할 수 있어야 한다.
기본적으로 데이터베이스는 다음과 같이 트랜잭션 관리를 위한 명령을 제공
- commit: 모든 데이터의 변화를 실제 적용
- rollback: 문제 발생시 현재까지의 변화를 원래대로 되돌림
A~C 순으로 진행되는 트랜잭션의 처리 과정을 요약하면 다음과 같다.
작업 A OK
작업 B OK
작업 C OK
commit
작업 A OK
작업 B OK
작업 C Fail
rollback -> A, B 는 모두 처리 이전값으로 복원됨.